Maximizing Client Throughput — Async vs Threads, Adaptive Rate Limiting, and Queue Resilience
TIP
Prefer a single authoritative limiter (circular buffer) and remove redundant sleeps. Add a small adaptive buffer for server-side timestamp skew to avoid 429s.
WARNING
If request generation > dequeue rate, your main queue will bloat and TTLs will expire. Add backpressure or increase consumer parallelism.
DANGER
Relying on a fixed latency buffer (e.g., always 50 ms) can silently cut your throughput on good networks or still 429 on bad ones. Use adaptive buffering.
Table of Contents
- Getting Started
- Folder Structure
- Introduction
- Benchmarking System
- Enhancing the Rate Limiter
- Improving the Queue System
- Addressing Queue Bloating
- Exploring Multithreading
- Comparison Between Asynchronous and Multithreading Client
- Overview and Modifications Summary
- Final Thoughts
Getting Started
pip install -r requirements.txt
# run the server
python3 original_server.py
# run async client
python3 async/client.py
# run multithreaded client
python3 thread/client.py
# run with memory profiling
mprof run python3 <MODEL>/client.py
mprof plot
Folder Structure
-
async/— asynchronous client (rate limiter, benchmark, queue manager) -
thread/— multithreaded client (thread-safe queue manager and limiter) -
original_client.py— baseline client -
original_server.py— baseline server
Introduction
This post reviews and optimizes a Python client designed to maximize throughput under server-enforced rate limits using multiple API keys. We identify bottlenecks in the original implementation, introduce an adaptive rate limiter, add queue resilience with a DLQ, and compare async vs threading under realistic load.
Benchmarking System
TIP
Benchmarks live in
async/benchmark.pyandthread/benchmark.py. Keep runner overhead minimal and print aggregate stats periodically.
Key Metrics Tracked
- Total Successful Requests — stability and efficiency under load
- Total Failed Requests — timeouts / 429s / network issues
- Average Latency (ms) — user-perceived performance
- Throughput (TPS) — sustainable capacity from start of run
How the Benchmarking System Works
- Records success/failure and latencies
- Computes moving average latency
- Derives throughput since benchmark start
- Prints metrics at fixed intervals for real-time feedback
Enhancing the Rate Limiter
Original Implementation
class RateLimiter:
def __init__(self, per_second_rate, min_duration_ms_between_requests):
self.__per_second_rate = per_second_rate
self.__min_duration_ms_between_requests = min_duration_ms_between_requests
self.__last_request_time = 0
self.__request_times = [0] * per_second_rate
self.__curr_idx = 0
@contextlib.asynccontextmanager
async def acquire(self, timeout_ms=0):
enter_ms = timestamp_ms()
while True:
now = timestamp_ms()
if now - enter_ms > timeout_ms > 0:
raise RateLimiterTimeout()
# Fixed Interval Check
if now - self.__last_request_time <= self.__min_duration_ms_between_requests:
await asyncio.sleep(0.001)
continue
# Circular Buffer Check
if now - self.__request_times[self.__curr_idx] <= 1000:
await asyncio.sleep(0.001)
continue
break
self.__last_request_time = self.__request_times[self.__curr_idx] = now
self.__curr_idx = (self.__curr_idx + 1) % self.__per_second_rate
yield self
Identified Issues
Two separate sleeps attempt to regulate rate:
- Fixed interval between consecutive requests
- Circular buffer enforcing N/second
They are redundant and cause extra context switches.
Proposed Solution
Remove the fixed interval; rely solely on the circular buffer (N requests per any sliding 1 s window). This reduces yield/scheduling overhead and still handles bursty and constant-rate traffic.
Observation: Performance Improvement
Throughput improved from ~74 TPS → ~85 TPS after removing the fixed interval check, primarily by cutting event-loop churn.
Potential Issue: 429 Errors Due to Latency
Even with a correct client window, server-side timestamps (affected by variable network latency) can observe Δt < 1000 ms between the 1st and Nth requests → 429.
WARNING
Timestamp skew of just a few milliseconds between client/server can flip a pass into a fail. Add a latency headroom.
Improved Version: Adaptive Buffering
class RateLimiter:
def __init__(self, per_second_rate, min_duration_ms_between_requests):
self.__per_second_rate = per_second_rate
self.__min_duration_ms_between_requests = min_duration_ms_between_requests
self.__request_times = [0] * per_second_rate
self.__curr_idx = 0
from collections import deque
self.__latency_window = deque(maxlen=100)
self.__buffer = 40 # ms
self.__min_buffer = 30 # ms
self.__max_buffer = 50 # ms
def update_buffer(self):
if self.__latency_window:
avg_latency = sum(self.__latency_window) / len(self.__latency_window)
self.__buffer = min(self.__max_buffer,
max(self.__min_buffer, int(avg_latency * 1.1)))
def record_latency(self, latency_ms: int):
self.__latency_window.append(latency_ms)
self.update_buffer()
@contextlib.asynccontextmanager
async def acquire(self, timeout_ms=0):
enter_ms = timestamp_ms()
# headroom: circular window (1000ms) + adaptive buffer
headroom = 1000 + self.__buffer
while True:
now = timestamp_ms()
if now - enter_ms > timeout_ms > 0:
raise RateLimiterTimeout()
if now - self.__request_times[self.__curr_idx] <= headroom:
sleep_time = (headroom - (now - self.__request_times[self.__curr_idx])) / 1000
await asyncio.sleep(sleep_time)
continue
break
self.__request_times[self.__curr_idx] = timestamp_ms()
self.__curr_idx = (self.__curr_idx + 1) % self.__per_second_rate
yield self
TIP
Still seeing sporadic 429s? Add exponential backoff with jitter on retries and clamp max in-flight requests per key.
Improving the Queue System
Issue
Request generation can outpace consumption: TTLs expire, wasting work.
Solution: Queue Manager with Dead Letter Queue (DLQ)
- Main Queue — normal flow
- DLQ — failures/timeouts for retry with capped attempts
- Graveyard — IDs exceeding max retries for later analysis
Retry Prioritization: Insert short cooldowns in producers so DLQ items can be re-slotted quickly (lightweight alternative to a strict priority queue).
Lifecycle with Queue Manager
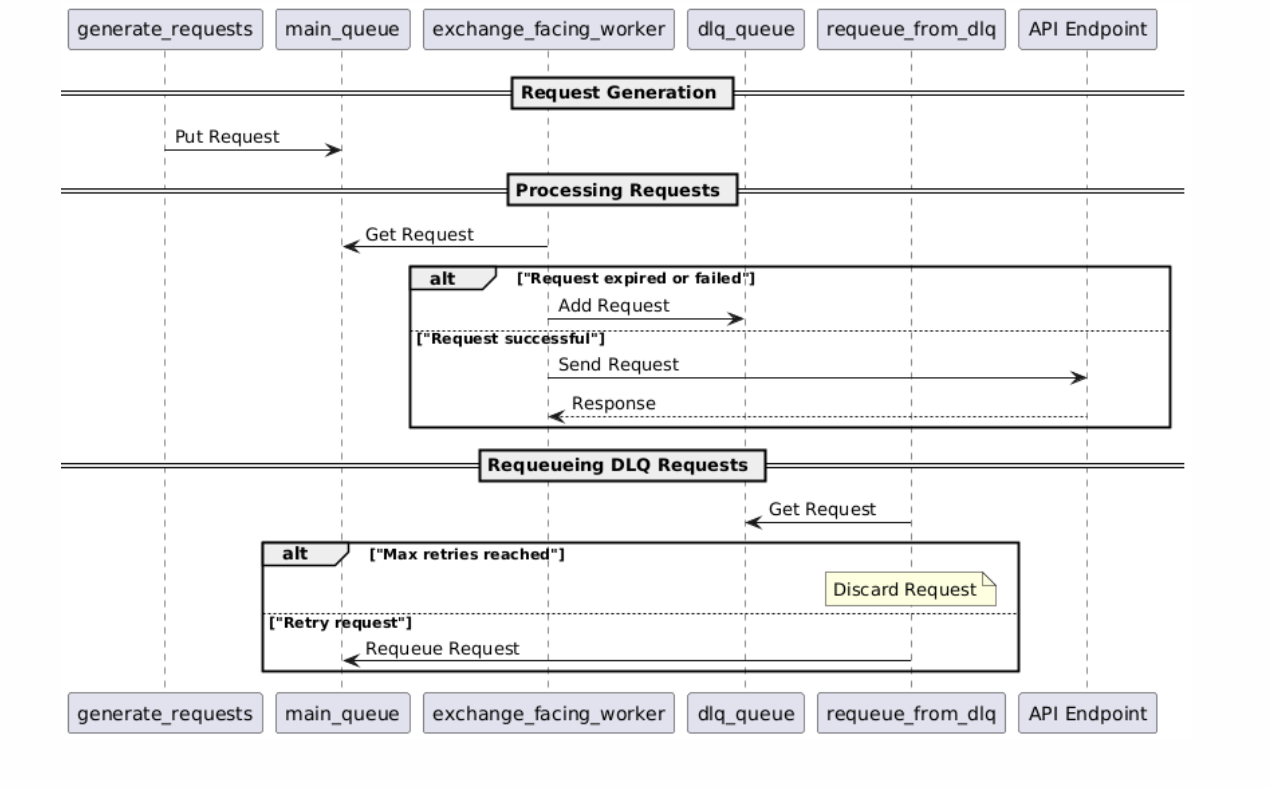
Monitoring the Queue
Log periodically:
- Main/DLQ sizes, processing rates, retry counts
- Graveyard size
Example:
--- Accumulated Benchmark Metrics ---
Elapsed Time: 10.00 s
Total Successful Requests: 834
Total Failed Requests: 0
Total Throughput: 83.38 req/s
Average Latency: 322.23 ms
Queue Sizes - Main: 40, DLQ: 0, Graveyard: 0
Average Queue Sizes - Main: 22.00, DLQ: 0.00
Addressing Queue Bloating
Root cause: generation rate > consumption rate with only 5 keys (5 consumers). Add backpressure to generate_requests():
if queue.qsize() >= max_queue_size:
await asyncio.sleep(0.5)
continue
Or increase consumer throughput (more keys/parallelism) or multithreading consumers.
Exploring Multithreading
Rationale
Multiple threads dequeue concurrently → fewer TTL expirations.
WARNING
Python’s GIL limits CPU-parallelism. Threads help I/O, but add contention and context switching.
Changes to the Current Code
-
Threaded Roles
- Request generator
- Exchange-facing workers (per API key)
- Queue manager (DLQ)
- Metrics/benchmark printer
-
Locks on Shared State
- Queue manager internals (DLQ, graveyard)
- If sharing a limiter across threads, make it thread-safe
-
Nonce Uniqueness
- Timestamp + thread-local counter or UUID
Comparison Between Asynchronous and Multithreading Client
Baseline Comparison
Async
- 5 key-workers (coroutines)
- 1 generator
- 1 DLQ manager
- 2 monitoring/benchmark coroutines
Threads
- 5 key-workers (threads)
- 1 generator
- 1 DLQ manager
- 2 monitoring/benchmark threads
Observation
Asynchronous (~84 TPS)
- Higher throughput, some queue buildup → TTL expirations (e.g., 13) under sustained overload.
Multithreading (~77 TPS)
- Slightly lower TPS; keeps queue near empty and avoids expirations.
CPU Utilization
- Async generally lighter; Threads contend on the GIL.
Summary
- Async: Best TPS / scalability for I/O; add backpressure to avoid TTL lapses.
- Threads: Best delivery reliability when avoiding expirations is critical.
Overview and Modifications Summary
Modifying the Original Client
- Removed redundant waits — rely on circular buffer limiter
- Added adaptive buffering — avoid server-side 429s from timestamp skew
- Introduced Queue Manager + DLQ + Graveyard — resilient retries
- Added backpressure — keep qsize bounded
- Optional threading — increase dequeue rate when keys are limited
Final Thoughts
Threading yields steady delivery with low queue sizes; Async delivers higher throughput with fewer resources. With adaptive rate control and backpressure, the async client becomes the long-term winner for speed, efficiency, and scale.
Enjoy Reading This Article?
Here are some more articles you might like to read next: